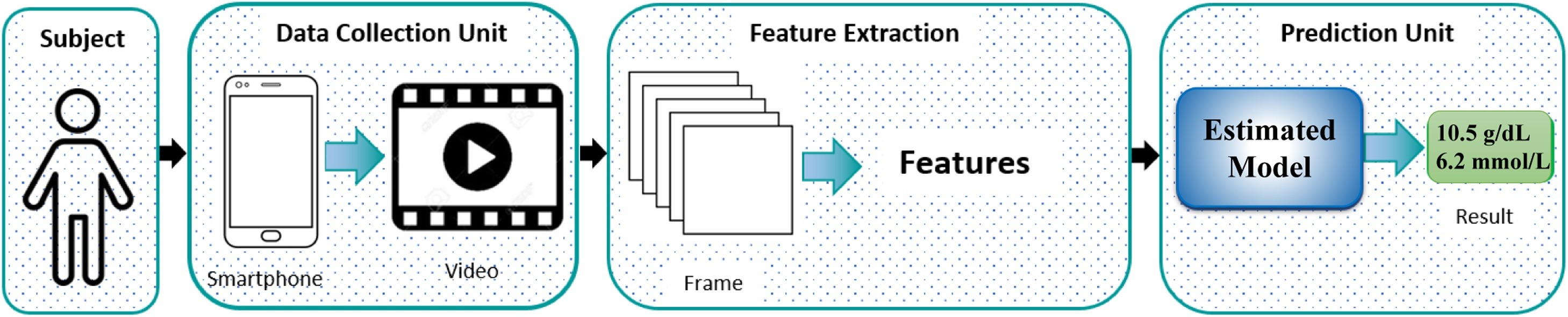
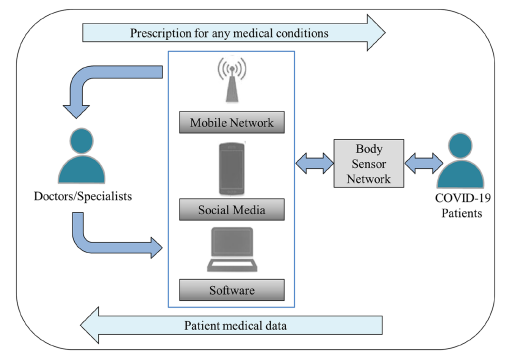
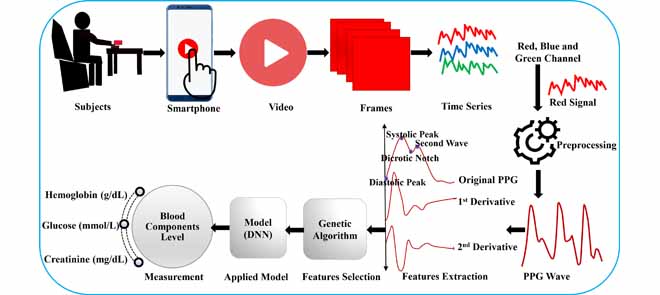
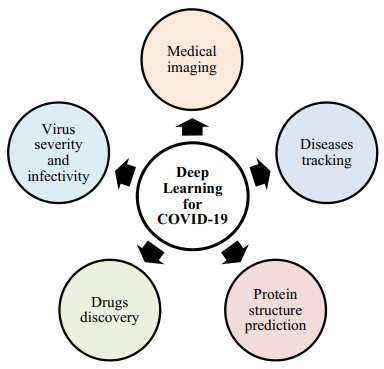
publications
Research publications across computer vision, deep learning, healthcare AI, and NLP. Also available on Google Scholar.
Research Publications
Contributions spanning sign language recognition, multimodal depression detection, medical image analysis, and healthcare AI
-- Publications
-- Conference
-- Journal
-- First / Equal Author
-- Awards
Conference Journal
Citation Impact
1289 Citations Since 2021: 1201
10 h-index Since 2021: 10
10 i10-index Since 2021: 10
Yearly Citations · Source: Google Scholar